Fokus
IT Strategy
Wir unterstützen Sie bei der Umsetzung Ihrer Unternehmensstrategie vom Ist-Zustand zum Ziel-Zustand. Abgeleitet aus den Anforderungen Ihrer Geschäftsziele, Visionen und den IT-Rahmenbedingungen heraus.
IT Tactics
Taktische Maßnahmen bilden mit IT-Operations und der IT-Strategie die Ebenen des IT-Managements. Unser Leistungsportfolio reicht von der Einführung eines KPI-gestützten Reportings bis hin zu Disaster Recovery Prozessen.
IT Security
Advanced Persistent Threats (APTs) sind komplexe, industrialisierte Projekte mit Sponsoren, einem Projektteam, einem Budget, einem Zeitplan und einem Plan. Informationssicherheit ist also kein Zufall. Sie ist auch ein komplexes Projekt mit Sponsoren, einem Projektteam, einem Budget, einem Zeitplan und einem Plan.
Excellence in execution
Information Security Management
Die Enterprise Open Systems (EOS) ist eine hochspezialisierte IT Consulting Manufaktur mit dem Kompetenzschwerpunkt Information Security Management.
In diesem sensiblen Kontext leisten wir unseren Partnern wichtige Beiträge bei der Gestaltung ihrer IT-Strategie und Taktik, um die gesetzten Security Ziele mit Sicherheit zu erreichen.
Wir sind branchenübergreifend tätig, verfügen jedoch über ausgezeichnete Erfahrungen in den Bereichen Finanzdienstleistungen, Versicherungen, Pharma, Chemie und Cloud-Anbieter.
Unsere Mitarbeiter verfügen über jahrzehntelange Expertise in den verschiedenen Aspekten der IT-Sicherheit und sind anerkannte Spezialisten mit verschiedenen Zertifizierungen.






Mehrwerte für Ihr Unternehmen
Die Enterprise Open Systems unterstützt ihre Kunden mit KnowHow, Erfahrung und Leidenschaft

Governance

Risiken

Compliance
Blog
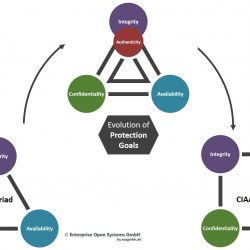
Schutzziele: CIA und CIAA
Schutzziele: CIA und CIAA Management Summary Die klassischen Schutzziele der Informationssicherheit sind Vertraulichkeit, Integrität und Verfügbarkeit. Diese drei Schutzziele werden oft als CIA-Triade bezeichnet, da die Anfangsbuchstaben der englischen Übersetzungen dieser Wörter gerade C, I und A sind.Inzwischen hat ein weiteres Schutzziel an Bedeutung gewonnen. Der BSI bezeichnete die Authentizität in der Vergangenheit als Teilbereich[…]
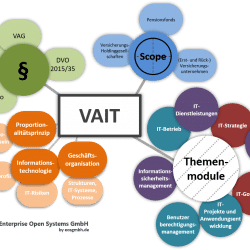
VAIT
Versicherungsaufsichtliche Anforderungen an die IT Management Summary Mit den Versicherungsaufsichtlichen Anforderungen an die IT (VAIT) formuliert die Bundesanstalt für Finanzdienstleistungsaufsicht (BaFin) klare Erwartungen an das Management und die Organisation der IT von Versicherungsunternehmen. Ziel der VAIT ist einerseits Transparenz durch verständliche Übersetzung bestehender Aufsichtsnormen in konkrete IT-Anforderungen zu schaffen. Andererseits soll das IT-Risikobewusstsein von Versicherungsunternehmen[…]

IT Budget für die Cloud
Checkliste für die Budget Planung Wer seine IT-Infrastruktur um Cloud-Ressourcen erweitern möchte – sei es in Form der private, public oder hybrid Cloud – stellt schnell fest, dass diese Umstellung auch eine Neuausrichtung des IT-Budgets erfordert – insbesondere die betriebswirtschaftliche Bewertung von Cloud Computing. Die Kostenrechnung von Cloud Services folgt anderen Regeln als die von On-premises-Architekturen.Aus unseren[…]

Cybersicherheit Glossar
In einer zunehmend vernetzten Welt, in der Gesellschaften auf digitale Infrastruktur angewiesen ist, bekommt das Thema Cybersicherheit/Cybersecurity einen zunehmend höheren Stellenwert. Dass Datenlecks immer häufiger vorkommen oder Hackerangriffe auf Stromversorger erfolgreich sind, zeigt, welche Auswirkungen mangelnde Cybersicherheit haben kann. Finden Sie in diesem Glossar eine kompakte Übersicht über die wichtigsten Begriffe, die Sie kennen sollten! Lesezeit[…]

Ihr Plan gegen Ransomware
Ihr 10 Punkte Plan gegen Ransomware Haben Sie auch in den Nachrichten von den Cryptolocker Infektionen gehört? In diesem Artikel erfahren Sie mehr über diesen Malware Typ und erhalten außerdem Vorschläge und Tipps zum Schutz vor Ransomware. Lesezeit 5 Minuten Was ist Ransomware? Im Laufe der letzten Jahre wurden wir Zeuge des Trends, dass Hacker[…]

Roadmap in die Cloud
Roadmap in die Cloud Autor: Carsten ReffgenFür IT-Verantwortliche ist die Einführung neuer Technologien immer eine Herausforderung und auch ein Risiko. Bei Cloud Computing kommen noch weitere Problematiken hinzu, da Cloud Computing auch die Prozesse und die Art der Zusammenarbeit mit anderen Abteilungen verändert. Im Folgenden möchten wir Ihnen eine Übersicht und Anregungen liefern, welche Themen[…]
Kontaktieren Sie uns
